


Siri Belajar AI : Mari Melatih GAN (Generative Adversarial Network) Bahagian 2


Alhamdulillah, sekali lagi, hujung minggu telah pun tiba. Tiba masanya untuk kita sambung belajar untuk terus memperbaiki diri dan menambahkan ilmu yang ada. Lebih-lebih lagi di bulan Ramadan ini. Kali ini, kita akan sambung mempelajari tentang GAN (Generative Adversarial Network). Seni bina rangkaian neural antara yang pertama yang membawa konsep generatif. Tapi sebelum kita melatih dulu GAN, kita perlulah memahami dulu strategi latihannya. Kita perlu tahu yang GAN membawa perpekstif yang berbeza dalam menggunakan fungsi kehilangan (loss function) dan juga backpropagation. Jadi sebelum kita pergi lebih jauh dulu, elok kita faham dulu apa itu fungsi kehilangan.
Sebelum nak latih, kita fahamkan dulu pasal Fungsi Kehilangan dia
Saya pernah ulas tentang fungsi kehilangan sebelum ini. Para pembaca boleh rujuk pada pautan di bawah: https://medium.com/@maercaestro/siri-belajar-ai-asas-model-bahasa-bahagian-2-5123795fa872
Di dalam ini saya hanya menceritakan tentang salah satu fungsi kehilangan (loss function) yang banyak digunakan dalam model bahasa (language model), iaitu negative log likelihood. Tapi sebenarnya, ada banyak lagi loss function (aku panggil loss function jelah pasni, kelakar pulak sebut fungsi kehilangan) yang wujud dalam dunia AI/ML. Dan loss function ini sebenarnya digunakan dalam proses latihan bagi menentukan sejauh mana prestasi latihan kita. Objektif latihan sebenarnya adalah untuk meminimumkan loss function kita serendah yang boleh. Dan itulah yang berlaku ketika proses latihan. Di mana backpropagation ini dilakukan secara berulang (iteratively) bagi mengurangkan loss function kita serendah yang boleh.
Nanti ada masa aku akan cuba ulas dengan lebih panjang berkenaan dengan loss function. Tapi buat masa ini, inilah yang para pembaca perlu tahu. Jadi apa bezanya dengan GAN?
Seperti yang kita sudah pelajari dalam siri lepas, GAN terdiri daripada generator dan discriminator. Fungsi generator adalah untuk menipu discriminator. Jadi, generator secara asasnya menggunakan negative log-likelihood (NLL) loss, yang juga dikenali sebagai cross-entropy loss. Dengan meminimumkan cross-entropy loss ketika latihan, diharapkan generator dapat menghasilkan imej palsu yang semakin realistik, sehingga sukar untuk ditentukan sebagai palsu oleh discriminator.
Discriminator pula berfungsi untuk menentukan sama ada imej yang dihasilkan oleh generator itu palsu atau tidak. Jadi, ia juga menggunakan cross-entropy loss tetapi dengan objektif yang berbeza. Discriminator berusaha untuk mengurangkan loss ini, kerana lebih rendah nilai loss function, lebih baik kemampuannya dalam mengenal pasti imej sebenar vs imej palsu. Namun, penting untuk ada keseimbangan dalam latihan. Jika loss discriminator terlalu rendah, ini bermaksud ia terlalu kuat, dan generator tidak dapat belajar dengan baik. Sebaliknya, jika loss discriminator terlalu tinggi, ini bermaksud ia gagal dalam klasifikasi, dan generator akan menghasilkan imej palsu yang tidak berkualiti.
Ok, sebelum kita pergi jauh, mari kita tengok dulu matematik dia macam mana. Mungkin dari situ kita boleh senang faham sikit.
Loss Function untuk Generator

Berpinar mata tengok kan? Hahaha…mari kita fahamkan satu-satu. Simbol E pelik tu sebenarnya mewakili “Expectation”. Satu nilai yang datang dari kebarangkalian. Katakanlah kita ada satu set guli berwarna warni (contoh yang biasa orang pakai masa sekolah dulu), warna merah, biru ataupun hijau. Kalau kita ambil secara rambang guli tersebut dari dalam plastik yang bertutup, kita nak tahu, apa warna yang kita boleh dapat.Ini yang kita panggil sebagai kebarangkalian. Dan kita nilai kebarangkalian ini berdasarkan berapa banyak jumlah guli berawarna itu mengikut kategorinya masing-masing. Dengan meletakkan nilai pada kebarangkalian tersebut, kita boleh membuat satu persamaan yang membolehkan kita meletakkan satu nilai jangkaan berdasarkan pada purata yang dikira daripada setiap kebarangkalian. Dan ini akan dikira bagi setiap warna yang kita ambil. Itulah yang dikenali sebagai “Expectation”
Kemudian kita ada istilah G(z) dan D(G(z)). G(z) adalah imej yang dihasilkan oleh generator, dan D(G(z) pula adalah ramalan kebarangkalan dari discriminator yang mengatakan imej dihasilkan oleh generator itu nampak tulen. Skala dia adalah dari 0 (palsu) ke 1 (tulin). Jadi dah tentulah kita nak mendapatkan yang paling dekat dengan nilai 1.
Persamaan di atas perlu ditambah nilai negatif di depan semasa latihan. Kerana yang kita inginkan adalah nilai loss dia. Nilai kehilangan dia. Dan nilai kehilangan itulah yang boleh digunakan untuk melatih model kita. Jadi dia akan jadi seperti di bawah.
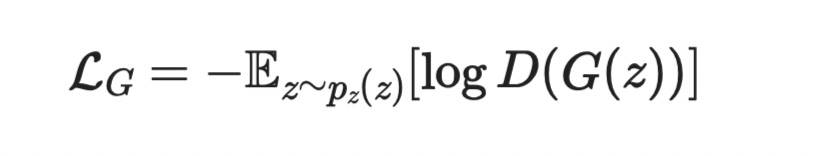
2. Loss function untuk Discriminator
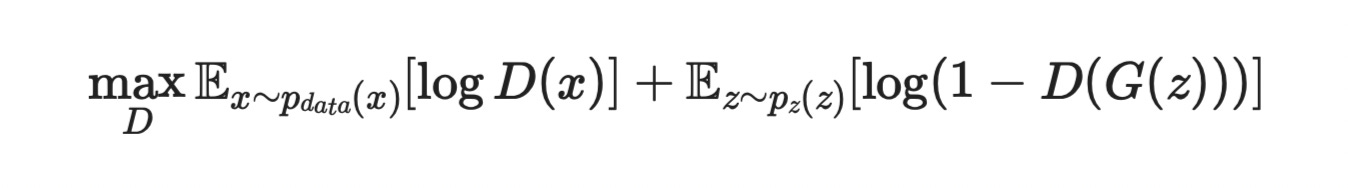
Discriminator mempunyai strategi yang berbeza dalam loss functionnya. Sebab fungsinya adalah untuk menentukan sama ada imej yang diberikan generator itu adalah imej yang betul ataupun imej palsu. Oleh kerana itulah, discriminator dilatih dengan data imej sebenar, berbeza dengan generator yang bermula dengan data rambang. D(x) dalam persamaam di atas merupakan nilai kebarangkalian yang imej itu tulen.. Dan nilai log D(x) ini perlulah digabungkan dengan kebarangkalian bahawa imej yang dihasilkan oleh generator itu palsu. Itu sebabnya kita letakkan fungsi log 1-D(G(z))
Jadi untuk loss function, kita perlu letak nilai negatif seperti biasa, jadi ia akan jadi seperti di bawah…

Mari Kita Melatih GAN
Sekarang kita dah faham loss function untuk GAN. Jadi kita dah boleh gunakan loss function GAN ni untuk kita punya latihan model. Untuk itu, kita akan melatih model kita dengan data CIFAR-10.
Apa itu data CIFAR-1O
Untuk yang tak tahu, CIFAR-10 (Canadian Institute for Advanced Research 10-class dataset) merupakan dataset imej yang sangat meluas digunakan sebagai dataset pengenalan kepada mereka yang ingin berkecimpung dalam bidang AI ini. Ia terdiri daripada 60,0000 gambar berwarna, masing-masing dengan saiz 32 piksel x 32 piksel. Gambar-gambar ini terdiri dari 10 kelas iaitu:
Kapal terbang
Kereta
Burung
Kucing
Rusa
Anjing
Katak
Kuda
Kapal laut
Lori/Trak
Kelas ataupun label yang saya tulis di atas adalah mengikut kelas yang ada di dalam dataset CIFAR-10 itu sendiri. Dataset ini memang direka untuk membolehkan kita melatih model kita untuk mengkelas ataupun imej-imej dalam katergori di atas. Ok, sekarang kita boleh tengok bagaimana untuk memuat turun data GAN untuk latihan. Dan ini boleh dilakukan dengan mudah menggunakan library pytorch (lebih spesifik torchvision.datasets).
Dataset ini terdiri daripada jalur piksel (32x32x3 =3,072 ) dan juga label. Setiap jalur piksel itu terdiri daripada lingkungan nombor dari 0 ke 255. Ini mewakili nombor HEX yang digunakan untuk menentukan warna dalam saluran RGB. Kalau siapa yang biasa main Photoshop tahulah saya cakap berkenaan apa. Jadi, disebabkan nilai data-data itu terlalu bertebaran jauhnya antara satu-sama lain, maka seeloknya kita normalizekan dia dari -1 ke 1 dan bukannya 0 ke 255. Kenapa -1 ke 1? Sebab itulah proses yang dilakukan oleh fungsi pengaktifan yang ada pada lapisan terakhir generator. Boleh refer pada siri yang lepas.
Bagaimana nak buat semua benda ni? Senang je, para pembaca hanya perlu jalankan kod di bawah,
import torch
import torchvision
import torchvision.transforms as transforms
# kat sini kita letak proses transformasi yang diperlukan
transform = transforms.Compose([
transforms.ToTensor(), #masukkan imej kita ke dalam tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # tukarkan nilai dari 0 -> 255 kepada (-1) -> 1
])
# muat turun training set CIFAR 10 yang terdiri daripada 50,000 gambar
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
# muat turun test set CIFAR 10 yang terdiri daripada 10,000 gambar
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# kita gunakan dataloader yang boleh menyusun data-data ini dalam bentuk Batch sebelum dihantar ke model
dataloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# buat semakan pada dataset yang sudah dimuat turun. pastikan kita ada 50,000 gambar latihan dan 10,000 gambar ujian
print(f"Sampel latihan: {len(trainset)}")
print(f"Sampel ujian: {len(testset)}")Jika berjaya, data akan dimuat turun, dan mesej akan terpampang di bawah:

Ok. Sebaik sahaja kita dah muat turun data-data kita, kita bolehlah terus bina model kita. Ingat tak dalam siri lepas kita sudahpun belajar macam mana nak bina model GAN? Kali ini pulak kita akan gunakan pytorch, sebab ia lebih mudah untuk latihan nanti. Apa yang kita perlu ada dalam model GAN kita hanyalah generator yang menghasilkan imej dari data rambang (bukan sebarang rambang, ia menggunakan taburan normal sebagai rujukan), dan discriminator yang menentukan sama ada imej itu palsu ataupun tulen. Para pembaca perlu menjalankan kod di bawah
import torch
import torch.nn as nn
import torch.optim as optim
# kelas GAN boleh dibina seperti di bawah:
class GAN(nn.Module):
def __init__(self, noise_dim=100):
"""
Membina satu kelas GAN asas yang terdiri dari:
1. Generator - yang menghasilkan imej dari data noise rambang
yang terdiri dari tensor 100 dimensi.
2. Discriminator - yang mengkelaskan imej itu tulen ataupun palsu
"""
super(GAN, self).__init__()
self.generator = Generator(noise_dim)
self.discriminator = Discriminator()
def generate(self, z):
return self.generator(z)
def discriminate(self, img):
return self.discriminator(img)
# Generator Class
class Generator(nn.Module):
def __init__(self, noise_dim=100):
"""
Generator menghasilkan imej dari data noise yang rambang
Boleh dilihat uang ia dihasilkan dari data bersaiz (1000,256)
sebelum dikecilkan kepada data bersaiz 32x32x3 mengikut
saiz dataset CIFAR 10
"""
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(noise_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, 32 * 32 * 3),
nn.Tanh() # tanh mengeluarkan output dengan skala -1 -> 1
)
def forward(self, z):
img = self.model(z)
img = img.view(-1, 3, 32, 32) #
return img
# Discriminator Class
class Discriminator(nn.Module):
def __init__(self):
"""
Dilatih dengan dataset CIFAR-1O bagi membolehkan ia mengenalpasti
imej yang palsu vs tulin
"""
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(32 * 32 * 3, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid() # meghasilkan output 0 ->1 . O untuk palsu, 1 untuk tulin.
)
def forward(self, img):
img_flat = img.view(img.size(0), -1) # Flatten image
validity = self.model(img_flat)
return validityOk. Kita dah bina model, mari kita bersedia dengan latihan. Untuk latihan kita akan menggunakan Adam sebagai optimizer dan ia akan dilatih pada 50 pusingan latihan dengan kadar latihan/pembelajaran yang berbeza untuk discriminator dan juga generator.
Kenapa kadar pembelajaran yang berbeza? Kerana discriminator biasanya akan belajar lebih pantas kerana ia hanya perlu mengeluarkan output binari semata-mata, berbanding dengan generator yang perlu menghasilkan imej.
Mari kita jalankan kod di bawah.
# Hyperparameters yang kita set
noise_dim = 100
batch_size = 64
epochs = 100 #berapa round kita nak latih
lr_d= 0.0001 #kadar latihan ataupun leraning rate untuk discriminator
lr_g = 0.002 #kadar latihan untuk generator
# kita bina model kita yang belum dilatih, boleh tengok fungsi loss kita adalah BCELoss (binary cross entropy loss
gan = GAN(noise_dim)
def weights_init(m):
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.zeros_(m.bias)
gan.apply(weights_init) # Apply this when initializing the model
adversarial_loss = nn.BCELoss()
optimizer_G = optim.Adam(gan.generator.parameters(), lr=lr_g, betas=(0.5, 0.999))
optimizer_D = optim.Adam(gan.discriminator.parameters(), lr=lr_d, betas=(0.5, 0.999))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
gan.to(device)
# loop latihan
for epoch in range(epochs):
for i, (real_imgs, _) in enumerate(dataloader):
real_imgs = real_imgs.to(device)
batch_size = real_imgs.size(0)
# hasilkan noise secara rambang
noise = torch.randn(batch_size, noise_dim, device=device)
fake_imgs = gan.generate(noise)
# Label data...
real_labels = torch.ones(batch_size, 1, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)
# kita latih discriminator dengan data
optimizer_D.zero_grad()
real_loss = adversarial_loss(gan.discriminate(real_imgs), real_labels)
fake_loss = adversarial_loss(gan.discriminate(fake_imgs.detach()), fake_labels)
d_loss = real_loss + fake_loss
d_loss.backward()
optimizer_D.step()
# latih generator
optimizer_G.zero_grad()
g_loss = adversarial_loss(gan.discriminate(fake_imgs), real_labels)
g_loss.backward()
optimizer_G.step()
# hasil latihan
if i % 100 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Langkah [{i}/{len(dataloader)}], Loss dari discriminator: {d_loss.item():.4f}, Loss dari generator: {g_loss.item():.4f}")
torch.save(gan.state_dict(), "gan_model.pth")
print(f"Model disimpan untuk epoch {epoch + 1}")
print("Latihan selesai! Model telah disimpan dalam gan_model.pth")Sebaik kita jalankan latihan, kita boleh nampak outputnya seperti di bawah.

Adalah amat penting untuk kita mencetak loss dari Generator dan juga discriminator. Kerana ini boleh membantu kita untuk memahami dinamika antara generator dan disciminator sewaktu latihan. Boleh nampak yang kita mempunyai loss yang tidak seimbang.
Pun begitu, kita boleh uji hasil latihan kita dengan kod di bawah:
import matplotlib.pyplot as plt
def generate_images(model, num_images=5, noise_dim=100):
model.eval()
with torch.no_grad():
noise = torch.randn(num_images, noise_dim)
generated_images = model.generate(noise)
generated_images = generated_images.cpu().numpy()
generated_images = (generated_images + 1) / 2
fig, axes = plt.subplots(1, num_images, figsize=(10, 2))
for i in range(num_images):
img = np.transpose(generated_images[i], (1, 2, 0))
axes[i].imshow(img)
axes[i].axis('off')
plt.show()gan = GAN()
gan.load_state_dict(torch.load('gan_model.pth'))
generate_images(gan)Dan ia akan menghasilkan 5 sampel imej seperti di bawah:

Kelihatan imej yang dihasilkan masih lagi kabur. Namun begitu, sebagai pengenalan, ia sudahpun cukup berjaya saya rasa. Ada banyak lagi benda yang kita boleh buat untuk memperbaiki latihan ini.
Tapi kuncinya hanya satu sahaja, iaitu memastikan latihan yang seimbang antara disciminator dan juga generator.